The x86-TSO Memory Model
Throughout the late 1990s and early 2000s, multicore processors slowly began to make their way into consumer hardware. It was in the interest of Intel and AMD that people knew how to develop software for their chips. So, naturally, they laid out a set of wildly ambiguous and contradictory principles for reasoning about memory visibility between cores.
Over time, experiments began to show that all x86 CPUs behaved the same in terms of memory ordering; it was just a matter of communicating that behaviour. Sewell, Sarkar, Owens, Nardelli, and Myre did exactly that in the paper ‘x86-TSO: A Rigorous and Usable Programmer’s Model for x86 Multiprocessors’.
As esoteric a topic as it seems, the x86-TSO provides an extremely
helpful way of reasoning about multithreaded / lock-free software. In
fact, it follows from this framework that, for x86, nearly all of C++’s
std::atomic memory orderings are the default. It becomes much easier to
understand these higher-level portable memory models, designed to deal
with weakly ordered architectures like ARM, when you frame them as a way
of enforcing x86’s strongly ordered semantics.
The Abstract Machine
The x86-TSO states that we can think about multithreaded execution with a simplified machine split into hardware threads and the memory subsystem, visualised within the dotted lines.
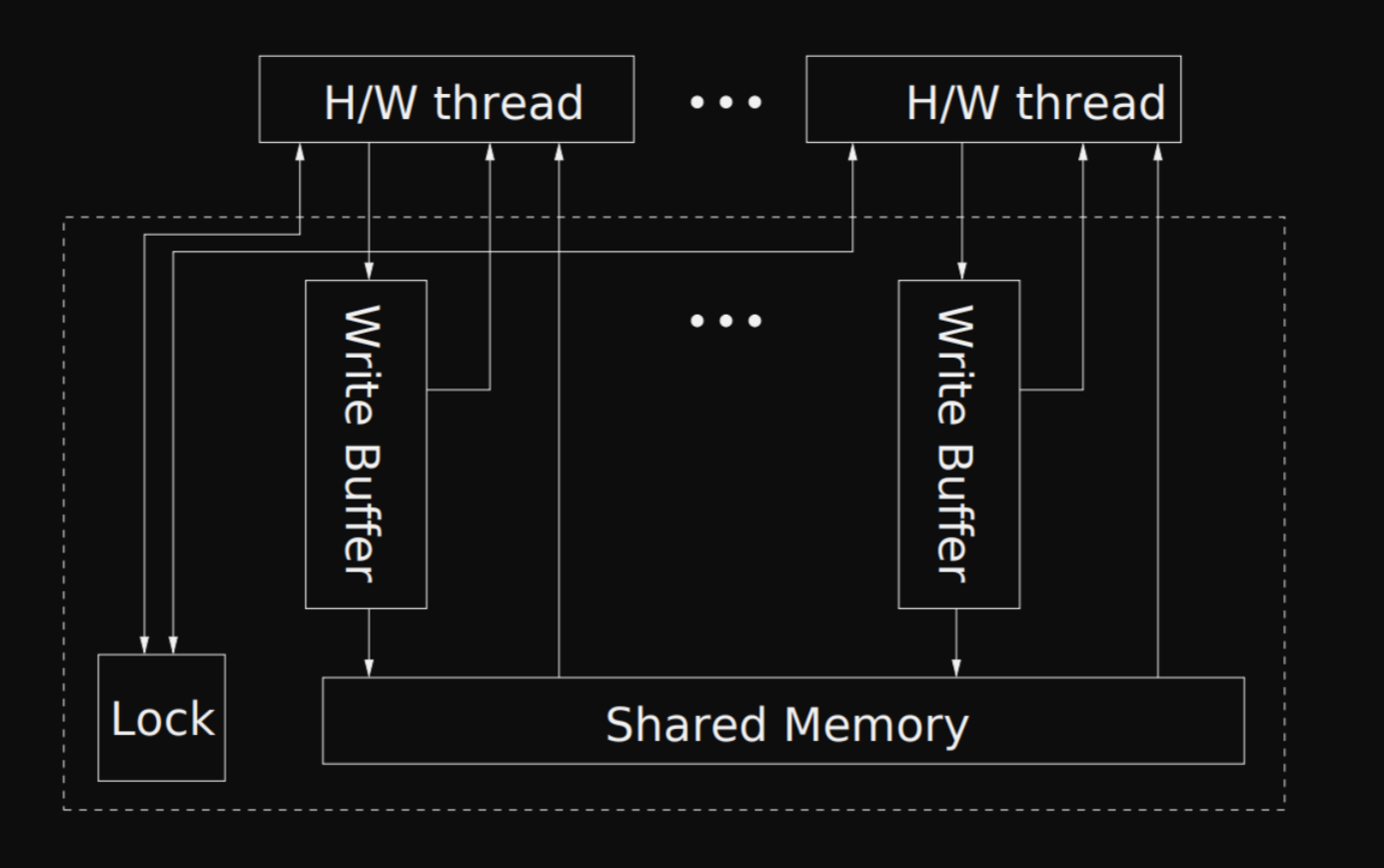
The interactions between a hardware thread and the memory subsystem can be summarised into five points:
- Every thread has its own FIFO store buffer.
- A thread will always read from its store buffer if it contains an entry for the target address.
- An MFENCE instruction flushes the thread’s store buffer to shared memory.
- A LOCK’d instruction executed by a thread will obtain the global lock, and before releasing it, flush the thread’s store buffer to shared memory.
- The oldest buffered store (FIFO) can be moved by the memory subsystem to shared memory at any time, except when another thread holds the global lock.
A more detailed explanation defines six interactions between a thread and the memory subsystem, known as events. There are constraints on when these events can occur. Together, these form a set of transitions between states of the memory subsystem, which can be used to formally verify possible orderings of memory visibility.
Events and Constraints
Here we present a slightly more precise version of the above. This will be helpful for reasoning about memory visibility in the next section of examples. Consider a thread blocked if some other thread holds the global lock.
The events, with their constraints as subpoints, are as follows:
- A thread can write to an address:
- at any time, but only to its store buffer.
- A thread can read from an address
- if it is not blocked, and only:
- from its store buffer if there is a buffered store.
- from shared memory if there is no buffered store.
- if it is not blocked, and only:
- A thread can issue an MFENCE barrier:
- once its store buffer is flushed to shared memory.
- A thread can start a LOCK’d instruction:
- if the lock is not held.
- A thread will release the lock over its LOCK’d instruction:
- once its store buffer is empty.
- The memory subsystem can move a write from one thread’s store buffer
to shared memory:
- if that thread is not blocked, and only:
- the oldest write (FIFO).
- if that thread is not blocked, and only:
The paper reasonably assumes an additional ‘progress condition’: the CPU makes an effort to fulfill event six. That is, the writes in the store buffer won’t sit there for eternity.
For those familiar with atomics in a language such as C++, these constraints directly imply the modification order guarantee.
Litmus Tests
In this section, we’ll reason about two examples provided by the paper, known as ‘litmus tests’. I highly recommend reading the remainder of the examples from the original paper (section 3.3).
In each of the below examples, consider T0 and T1 to be hardware
threads with x and y as memory addresses, each holding the value
0.
1: Store-Store Reordering
Under the x86-TSO, can stores be reordered relative to other stores? Put
concretely, could any execution of the below program result in the final
state [T1: eax = 1, ebx = 0]?
T0: | T1:
mov [x] <- 1 | mov eax <- [y]
mov [y] <- 1 | mov ebx <- [x]
We know that no thread is blocked. So, using the events and their constraints:
-
followed, in order, by
[y] <- 1. -
shared memory twice.
-
ebx <- [x], from shared memory (as T1 has no store buffer entries for these addresses).
Together, this means the final state is impossible. If T1 finds that
eax = 1, then it observed T0’s write [y] <- 1. Due to the
FIFO ordered store buffer, it follows that T0’s earlier write [x]
<- 1 was also moved to shared memory. This means T1 will always
observe T0’s write [x] <- 1, given it observed [y] <- 1.
This is the synchronises-with relationship in C++. If T1 observes T0’s store
[y] <- 1, then T1 must also have observed all of T0’s earlier operations, meaning the two are now ‘synchronised’.
2: Store-Load Reordering
Given that a load from shared memory may be fulfilled before the
subsystem propagates an earlier store, the x86-TSO allows for loads to
be reordered with older stores. This means that for the below, it is
possible to have [T0: eax = 0] AND [T1: ebx = 0] as a final
state.
T0: | T1:
mov [x] <- 1 | mov [y] <- 1
mov eax <- [y] | mov ebx <- [x]
This example rules out sequential consistency as the default - a common but misleading way of thinking about multicore execution.
You can visualise sequentially consistent execution as some interleaving of instructions, each with immediate memory visibility across cores. One interleaving might be:
T0: | T1:
mov [x] <- 1 |
| mov [y] <- 1
mov eax <- [y] |
| mov ebx <- [x]
Now, if x86 were sequentially consistent, then for any possible interleaving of the above instructions:
- Within a thread, the load must execute after the store becomes visible.
- Between the threads, one of the two stores must execute first.
Pairing these, T0’s load eax <- [y] must execute (with immediate
visibility) after T1’s store [y] <- 1, or vice versa. This
requires [T0: eax = 1] OR [T1: ebx = 1] as the final state,
but we just showed the exact opposite is possible under the x86-TSO.
To enforce sequential consistency, we can make use of the MFENCE or LOCK’d instructions. These directly flush the executing thread’s store buffer, or require a flushing of its store buffer, respectively.
T0: | T1:
mov [x] <- 1 | lock mov [y] <- 1
mfence | mov ebx <- [x]
mov eax <- [y] |
You could also use MFENCE on T1 with a LOCK on T0, or any other combination. The example uses both to demonstrate their equivalence in this scenario.
The Linux Kernel Spinlock
In 1999, Manfred Spraul, a contributor to the Linux kernel, proposed an optimisation to the existing x86-32 spinlock. The purpose of such a lock is to provide threads one-at-a-time access to a critical section marked by ‘enter’. It also requires that acquiring the lock ‘synchronises-with’ any previous release on any other core. That is, we require all memory operations executed within the section to become visible atomically, alongside the release of the lock. This enforces a sequentially consistent execution of that section between threads.
The suggested change was to remove the LOCK prefix from the final
mov in the release section of the below optimised code. The patch
was (incorrectly, in hindsight) denied by Linus
Torvalds.
acquire:
lock dec [eax] ; atomically decrement [eax]
jns enter ; if result >= 0, we got the lock
spin:
cmp [eax], 0 ; test [eax]
jle spin ; if [eax] <= 0, keep spinning
jmp acquire ; try to acquire again
enter:
... ; critical section
release:
mov [eax] <- 1 ; unlock (previously a LOCK'd mov instruction)
To understand why it was denied, we need to briefly touch on how the
spinlock works. eax points to a count, where 1 implies the spinlock
is available, and 0 or less that it is acquiredd. The optimised spinlock
works as follows:
lock dec [eax]will repeat until a count of 1 is read, each time:- acquiring the global lock on the memory subsystem,
- performing a read-modify-write decrement,
- flushing its store buffer to shared memory (as required to release the global lock),
- releasing the lock.
- The spinlock is acquired, and the critical section executes.
- The count is set back to 1.
By the x86-TSO, we know that the propagation of these thread-local operations on memory is FIFO ordered. So, if another thread observes that the spinlock was unlocked, then it must also observe all the effects on memory resulting from the operations that the unlocking thread executed within the critical section. This is fine.
However, at the time, this was not understood to be strictly true; Intel
and AMD x86 manuals had poorly specified this behaviour. For that
reason, the maintainers believed that a thread could observe a count of
1 without the previous operations yet having propagated to shared
memory. So, they required that the mov be LOCK’d to ensure that the
entire store buffer was atomically flushed alongside the restoration of
the count.
Summary
The x86-TSO provides programmers a convenient way to reason about memory
visibility across cores using a simplified abstract machine.
Higher-level languages require extremely complex memory ordering rules
due to portability. Despite this, you can still develop an intuition for
them by reasoning through a simpler memory model, such as the x86-TSO. I
hope to build on top of this post in the future, extending these ideas
to the C++ std::atomic memory orderings.